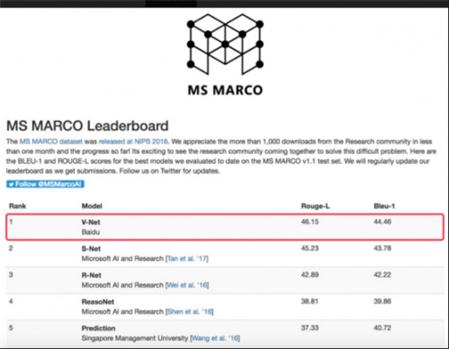
2月23日消息,近日在微软的MS MARCO机器阅读理解测试上,百度自然语言处理团队提交的V-NET模型以46.15的Rouge-L得分摘夺桂冠。

MS MARCO是微软在2016年10月份时发布的数据集,该数据集由10万个问答所组成,所有问题均是经过匿名处理后的真实问答数据,AI研究人员可用其来构建与真人相媲美的问答系统。
百度自然语言处理团队成立于2010年左右,目前团队拥有自然语言处理、数据挖掘、信息检索、机器学习、机器翻译等多个垂直领域人才。这个部门的职责之一便是为百度众多产品提供NLP模型算法,NLP经过了这几年的发展,在对话系统、语义理解方面均有了突破性的进展。
该团队首席科学家兼百度技术委员会主席吴华表示:“此次对于百度机器阅读理解技术而言,仅是一次小考,百度希望能够与领域内的其他同行者一起,推进机器阅读理解技术和应用的研究,使AI能够理解人类的语言、用自然语言与人类交流”。
 扫一扫获取最新精彩内容与学习资料
扫一扫获取最新精彩内容与学习资料
人工智能技术网 倡导尊重与保护知识产权。如发现本站文章存在版权等问题,烦请30天内提供版权疑问、身份证明、版权证明、联系方式等发邮件至1851688011@qq.com我们将及时沟通与处理。!:首页 > 大数据 » 百度自然语言处理团队V-Net模型拿下微软MS MARCO测试桂冠